2019. 9. 20. 15:25ㆍML, OpenCV/Tic-Tac-Toe 게임
준비
- Windows 10
- Python
- Tic-Tac-Toe Dataset
Tic-Tac-Toe게임
학습을 진행하기 전에 학습할 데이터의 분석과 게임 구현을 위해 Tic-Tac-Teo 게임의 규칙을 알아봤습니다.
Tic-Tac-Toe게임은 9칸의 공간에 한 명은 ‘O’ 다른 한 명은‘X’를 번갈아 그리며‘O’나 ‘X’ 3개가 직선으로 이어지게 만들면 승리하는 게임입니다.
아래 그림은 전체적인 프로그램 실행 순서를 도식화 해 놓은 그림입니다.
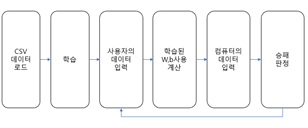
Tic-Tac-Toe게임은 바둑돌로 하는 오목게임과 비슷합니다.
3행 3열 총 9칸에서 두는 삼목 게임이라고 할 수 있겠네요.

Tic-Tac-Toe Dataset
학습을 위해서는 학습할 데이터가 필요하기 때문에 데이터의 구현이 필요했습니다.
3*3개의 칸을 채워야 하기 때문에 경우의 수는 최대 9! = 362880 개입니다.
모든 경우의 수를 데이터로 만드는 것이 가장 정확하겠지만 이미 승부가 났거나 승부가 명확할 때 실제 경우의 수는 줄어들며 Perceptron을 사용하면 훨씬 적은 경우의 수로도 승패를 알 수 있습니다.
직접 데이터를 만드는 것에는 많은 시간이 소용되기 때문에 학습을 하기 위해서 이미 만들어진 Tic-Tac-Toe 데이터를 사용했습니다.
데이터는 컬럼 이름을 제외한 (958,10)행렬로 되어 있으며 1번째 열부터 9번째 열은 게임에서 9칸에 놓인 말들의 정보가 담겨있고 10번째 열에는 승패 결과가 담겨있습니다.
데이터의 첫번째 행에 들어있는 실제 데이터 [O, O, O, O, X, X, O, X, X, true]이며 게임에서는 아래와 같은 모양을 가집니다.
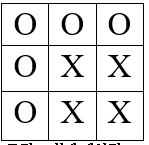
데이터의 1행 10열 [O, O, O, O, X, X, O, X, X, true]에서 ‘true’는 승 ‘false’는 패를 나타내고 결과는‘true’이기 때문에 ‘O’를 기준으로 승패를 나눴다는 것을 알 수 있습니다.
Perceptron이란?
Perceptron은 딥러닝 기계학습의 기초가 되는 인공신경망의 한 종류로 1957년 프랑크 로젠블라트에 의해 고안 되었습니다. 각 노드의 가중치와 입력을 곱한 것을 모두 합한 값이 활성함수에 의해 판단되고 값이 임계치보다 크면 결과값으로 1을 출력하는 특성을 가집니다.
Perceptron의 이러한 특성을 이용하여 Tic-Tac-Toe데이터를 학습시키고 학습시킨 후 도출되는 가중치와 편향 값을 사용하여 컴퓨터와 사람이 대결하는 Tic-Tac-Toe게임을 구현합니다.
데이터 전처리
불러온 데이터는 학습에 사용할 수 있는 형태로 만들어줍니다. 현재 데이터는‘O, X, b, true, false’와 같은 문자로 되어있기 때문에 이대로 학습을 진행하면 오류가 발생해 학습을 진행할 수 없습니다.
원활한 학습 진행을 위해 CSV 파일의 데이터를 수정했습니다.
|
변경 전 |
O |
X |
b |
True |
false |
|
변경 후 |
1 |
-1 |
0 |
1 |
0 |
그리고 불러온 데이터 행렬을‘float32’로 형 변환했습니다.
기계학습에서는 학습도 중요하지만 올바르게 학습되었는지 평가하는 과정도 중요합니다.
때문에 하나의 덩어리로 이루어진 데이터를 학습데이터와 테스트데이터로 나눕니다.
학습 데이터는학습을 진행하는데 쓰이고 나누어진 테스트데이터는 평가하는데 쓰입니다.
테스트 데이터는겹치지 않기 때문에 제대로 된 평가가 가능합니다.
학습과 평가를 위해 X의 학습데이터와 테스트데이터테스트 데이터, y의 학습데이터와 테스트데이터 총 4개의 변수 (X_train, X_test, y_train, y_test)를 를 사용해서 데이터를 나눴습니다.
데이터를 나누는 기준은 정해져 있지 않지만 보통 8:2 혹은 7:3으로 나누어 줘야 어느 한쪽에 치우치지 않고 제대로 학습과 평가가 가능하다는 견해가 있기 때문에 이 점을 참고해서 데이터를 8:2비율로 나누고 데이터를 무작위로 섞었습니다. 데이터 나누기는 파이썬의sklearn라이브러리를 사용했습니다.
*각각의 데이터 행렬(Shape)은 다음과 같습니다.
|
X_train |
X_test |
y_train |
y_test |
|
(670, 9) |
(288, 9) |
(670, 1) |
(288, 1) |
Tensor flow로 학습하기
학습에는 딥러닝에 특화된 라이브러리인 Tensorflow를 사용했습니다.
입력(X)과 출력(Y)을 ‘tf.placeholder’함수를 사용해서 변수를 선언했습니다.
‘placeholder’ 함수는생성될 때 값을 가지지 않고 일단 자리를 차지하는 개념입니다.
학습을 통해 찾아야 하는 값인 가중치 매개변수(W) 그리고 편향(b)를 선언합니다.
다음으로 간단한 학습모델을 만들었습니다. ‘tf.sigmoid’ 함수와 ‘tf.matmul’함수를 이용해서 affine계층과 활성화함수를 거쳐 값을 출력하는 모델 입니다.

학습에는 손실 함수인 ‘교차 엔트로피 오차’와 손실 함수의 최솟값을 구하는 ‘경사 하강법’을 사용하며 반복 학습합니다.
정답이 0과 1 뿐인 분류 문제이기 때문에 손실 함수로교체 엔트로피 오차’를 사용했습니다.
‘교차 엔트로피 오차’는 정답일 때의 모델 값에 자연로그를 계산하는 식을 가지며 만약 정답이 1이라고 했을 때, 정답에 근접하는 경우 오차가 0에 수렴해가지만 정답에서 멀어지면 (0에 근접하는 경우) 오차는 증가합니다.
따라서 학습을 위해 앞의 신경망 모델에서는 Sigmoid함수를 사용해서 데이터의 출력을 0과 1로 구분했습니다.
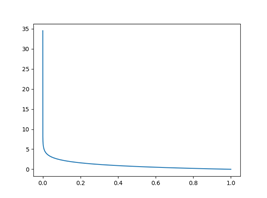
경사 하강법
손실 함수는 가장 작은 값이 나올수록 정답에 가깝기 때문에 가장 작은 값을 찾기 위해 ‘경사 하강법’을 사용합니다.
‘경사 하강법’은 손실 함수의 첫 위치에서 기울기 즉, 손실함수의 미분 값을 구해주고 기울기가 (+)라면 음의 방향으로,
(-)라면 양의 방향으로 일정 거리만큼 이동 후 그 위치에서의 기울기를 다시 구하는 방법입니다.
tensor flow를 사용했기 때문에 아래와 같이 간단한 코드로 ‘경사 하강법’을 구현할 수 있습니다.
tf.train.GradientDescentOptimizer().minimize()
Yeowoolee/Perceptron-Tic-Tac-Toe-game
Contribute to Yeowoolee/Perceptron-Tic-Tac-Toe-game development by creating an account on GitHub.
github.com